Nächste Seite: Problemfall K[omega]K Aufwärts: Möglichkeiten der Codierung Vorherige Seite: Bestimmung der Zeichenhäufigkeiten: Inhalt
LZW basiert auf einem ``Wörterbuchverfahren'' mit einem Wörterbuch von bis zu 4096 möglichen Einträgen und einer festen Codelänge von 12 bit. Das Wörterbuch wird wie bei allen LZ-Verfahren während des Kompressions- bzw. Dekompressionsvorgangs aufgebaut. Eine Ausnahme bilden die ersten 256 Einträge, die von vornherein mit den Abbildungen der einzelnen Bytes vorbelegt sind. Zur Laufzeit werden aus den Eingabedaten Muster gewonnen, die, sofern sie noch nicht bekannt sind, ins Wörterbuch eingetragen werden. Im anderen Fall wird nicht das Muster sondern sein Index im Wörterbuch ausgegeben.
Eingabe Erkanntes Muster Wörterbucheintrag
abrakadabra a ab
brakadabra b br
rakadabra r ra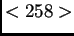
akadabra a ak
kadabra k ka
adabra a ad
dabra d da
abra ab
ra ra
Jede Zeile im Beispiel zeigt jeweils den Inhalt des Eingabestrings in jedem Schritt der Kodierung, das in diesem Schritt längste im Wörterbuch gefundene Zeichenmuster und neu hinzugekommene Wörterbucheinträge mit ihren Indexnummern.
Im ersten Schritt wird das längste gefundene Muster zwangsläufig nur
ein einziger Buchstabe sein, da beim LZW-Verfahren das Wörterbuch
mit allen Einzelzeichen mit den Codewerten von 0 bis 255 vorbelegt
ist, aber keine längeren Zeichenketten enthält. In unserem Beispiel
findet der Algorithmus also das 'a'. Im gleichen Schritt wird noch ein
weiteres Zeichen der Eingabe betrachtet ('b') und an das 'a' angehängt.
Die so erzeugte Zeichenkette ist garantiert noch nicht im Wörterbuch
enthalten, wird also unter dem Index 256 neu eingetragen.
Im nächsten Schritt wird vom Eingabestrom die im letzen Schritt
längste gefundene Zeichenkette (also das 'a') entfernt und ausgegeben.
Das 'b' wird nun zum ersten Zeichen des neuen Eingabestrings. Hier
beginnt das gleiche Spiel von vorne. 'b' ist das längste bekannte
Muster. 'br' wird unter dem Index 257 ins Wörterbuch
aufgenommen. 'b' wird von der Eingabe entfernt, ausgegeben und ein
neuer Durchlauf begonnen. 'r' ist nun längste im Wörterbuch
eingetragene Zeichenkette, 'ra' wird mit Indexnummer 258 neu
aufgenommen und das 'r' aus der Eingabe gestrichen und zur
Ausgabe umgeleitet.
'a' ist nun längste im Wörterbuch
eingetragene Zeichenkette, 'ak' wird mit Indexnummer 259 neu
aufgenommen und das 'a' aus der Eingabe gestrichen und zur
Ausgabe umgeleitet.
'k' ist nun längste im Wörterbuch
eingetragene Zeichenkette, 'ka' wird mit Indexnummer 260 neu
aufgenommen und das 'k' aus der Eingabe gestrichen und zur
Ausgabe umgeleitet.
'a' ist nun längste im Wörterbuch
eingetragene Zeichenkette, 'ad' wird mit Indexnummer 261 neu
aufgenommen und das 'a' aus der Eingabe gestrichen und zur
Ausgabe umgeleitet.
'd' ist nun längste im Wörterbuch
eingetragene Zeichenkette, 'da' wird mit Indexnummer 262 neu
aufgenommen und das 'd' aus der Eingabe gestrichen und zur
Ausgabe umgeleitet.
Im nächsten Schritt passiert endlich etwas interessanteres; das längste
bekannte Muster ist nun eine Zeichenfolge, die wir selbst ins
Wörterbuch eingetragen haben ('ab' mit Indexnummer 256). Jetzt
werden im nachfolgenden Schritt nicht zwei Einzelzeichen
ausgegeben, sondern der Index des Musters aus dem Wörterbuch
(256).
Das selbe geschieht nun auch bei der nächsten Zeichenkette 'ra' ist in
unserem Wörterbuch unter der Indexnummer 258 eingetragen. Es
wird also wieder nur der Index des Musters ausgegeben.
Die Ausgabe würde also wie folgt aussehen:
a b r a k a d ![]()
![]()
Dekodierung:
Eingabezeichen C Neuer Wörterbucheintrag PAusgabe: a b r a k a d ab ra
a a
b b ab=
r r br=
a a ra=
k k ak=
a a ka=
d d ad=ra
Bei der Dekodierung fangen wir ebenfalls mit einem schon vorinitialisierten Wörterbuch an. Wieder sind Einträge von 0 bis 255 vorhanden. In unserem Beispiel ist 'a' die längste bekannte Zeichenkette. Sie wird deshalb auch ausgegeben und in der Variablen P (wie 'Präfix') festgehalten. Die nächste Eingabe ist ebenfalls ein bekanntes Zeichen. Dieses wird zunächst in der Variablen C gespeichert. Nachfolgend wird P mit C konkateniert und das Ergebnis ins Wörterbuch unter der Indexnummer 256 aufgenommen. Man beachte, daß 'ab' sowohl im Dekompressor als auch im Kompressor an der gleichen Stelle im Wörterbuch vorkommt (256).
Nachfolgend wird die letzte Eingabe ('b') in die Variable P kopiert und P ausgegeben. Der nachfolgende Schritt (mit 'r') funktioniert genauso.
Kommen wir zu dem Punkt an dem der erste Index eingelesen wird. Hier wird nur das erste Zeichen des Wörterbucheintrags nach C übernommen ('a'). Dann wird wieder P und C konkateniert und ein neuer Wörterbucheintrag erzeugt ('da' mit Index 262). Jetzt wird P der Index 256 zugewiesen und der dazugehörige Wörterbucheintrag ausgegeben.